![]()
Advocacy
Dojo (HowTo)
Reference
Markets
Museum
News
Other
![]()
Myths
Press![]()
General
Hack
Hardware
Interface
Software![]()
Standards
People
Forensics![]()
Web![]()
CodeNames
Easter Eggs
History
Innovation
Sightings![]()
Opinion![]()
Martial Arts
ITIL
Thought![]()

![]()
![]()
![]()
|
Hit counters are little programs that try to keep track of how many visitors a site has (or a page has) -- but they can work a variety of ways, that give dramatically different results. Over the weekend I decided to finally do some real analysis of my site (log analysis), to figure out how far off my hit counter was. I've only been doing the site for a year and a half, and finally decided, "why not figure out how many people were actually visiting." Was I ever surprised.
The Problem (What is a hit?)
A visitor is a person that comes to a site. A page "hit" is each time a visitor loads a whole page. But technically a "hit" (Web Server Hit) is any file sent from the server (web site) to the client (web browser).
As a WebMaster, I care about page hits (how many visitors have loaded a page), but the web server gives me server hits (how many files the client has loaded) -- but these are dramatically different things.
A web "page" that a user sees can be made up of many different files -- each file registers a server hit. This can mean that a true "hit counter" can result in numbers that show numbers 5, 10 or 20 times the actual number of visitors to that page. Let me explain how a page can register multiple hits:
- An "page" is made of an HTML file (the text), and can
have many graphics in it. Each graphic image (gif or JPEG
files) is a separate file. So if we send 4 files (page
and 3 graphics) that means that one "page" actually
registers 4 hits.
- It gets worse. Some people use Server Side Includes
-- which is where an HTML file can include certain other
files, that are automatically "added" (included) in to
that HTML file. Sometimes those other "included" files
are counted as a hit (file), and sometimes not.
- I use Server Side Includes a
bit, so have about 8-9 file fragments (included files)
in every page -- but my server does not log them as
separate hits (I only get hit as one).
- I use Server Side Includes a
bit, so have about 8-9 file fragments (included files)
in every page -- but my server does not log them as
separate hits (I only get hit as one).
- Some Web Sites use frames. Framed sites have one
"frame" file that just defines where and which other HTML
files will be embedded (each in their own little frame).
That can be 2 to 10 HTML files per page again -- not
counting whatever graphic files may be embedded into each
of those HTML files.
- JavaScript and various CGI's can conditionally include files, that may or not be counted as a "hit".
This image should show what I mean:
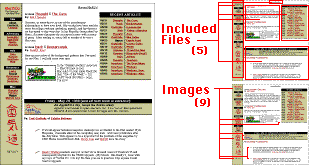
Notice that one page may have many included files and many images. My home page is actually made up of many fragments that all get included, and there are many small graphics (mostly for icons, but also for unusual things like shadowing the bottom of some tables).
But a "hit" isn't always as inflated a number as it seems. Sometimes the architecture can artificially deflates the actual numbers as well. Imagine you visit my page. Your browser "caches" on your hard-drive, a local copy, of the page and graphics (and separate frames if I was using them). The next time visit my site, the browser will pull as much from the local hard drive cache as it can. So the first time you go to a page, it may count 5 or 10 hits. The next time it could be half that, it could be one, or it could be zero (and pull everything from the cache). This means that you can visit my site without even registering a single hit, if it gets pulled from cache, since nothing at all gets loaded from the server (the site). More common is that the images get pulled from the cache, but the page will be pulled from the server -- meaning we are back down to a single hit.
Of course, all that caching is dependent on the client -- and whether you have caching on at all (most do). But there are so many factors -- like how big your cache is, and how much you browse. If you browse a lot (and your cache is small), then the browser will like have to flush the cache to use that storage for other sites (so it is no longer available to speed up my site). So everything can change depending on settings I don't control.
More Caches and Proxies: Just in case client caching isn't complex enough, there is also another kind of caching. Between most computers and your destination server, there are other computers (routers, proxy servers, caches and firewalls). These in between computers, most commonly proxy-servers, can cache information for a whole group of computers. So in your corporate office, when you load a page through a proxy, it will remember that page. The next time someone else in the company tries to load that page, it can pull that page out of ITS local cache (to keep the load to the outside world even smaller). Of course that also means that it doesn't register a "hit" on the server at all. And you are not always safe from proxy servers at home, since your ISP (Internet Service Provider) may have a proxy server between you and the host as well.
To make things even worse, some site's web counters are counting visitors to a particular page, and others are counting the total number of visitors to the entire site (all the pages). So if you are expecting a "site wide" counter, and implement a page counter, you may get really low numbers.
So you can see that a hit is something (a file being sent), but it is not always the same something. Sometimes it can mean a partial file, or sometimes not -- and it varies from Server to Server (and site to site) -- or even by preferences set inside of an individual brand of server, or who's add-in's to your server you are using. And it also varies by client, and their cache settings, and their browsing behavior. And it also varies based on what ISP you are using or how you are connected to the Internet (and whether there is a proxy server).
Counters
Most people (web masters) decided that the way to accurately display "visitors" is not to display server hits. Some do count "server hits" because it makes their sites look more popular, or they use those false counts to sell ad space. Some webmasters just lie and make up their hit counts, or have ways of inflating the numbers. So you can never trust web counts, unless you trust the webmaster.
Most counters work better than just server hit counters (remember, most web sites do NOT use server hit counters for their counts). The most common counters are CGI-based counters. CGI's are little programs that load and run on the server. These programs get run once per page, and all they do is add to a counter (and display the total), and display the information on the page as an image. The problem is that they are displayed in a browser as an image -- but at least there is only one of these per page (instead of many). So these are better at getting close.
Remember that the browser (or proxy) will sometimes cache the image, and not reload it, so the counter CGI may not get run all the time (unless the browser has to reload that image) -- depending on a few things. And of course things still get cached, so the page still may not be loaded at all when you visit (unless something has changed) -- but CGI's are much better for getting around most of the caching problems (just not perfect).
A few CGI counters, cache the address that the user called in from (your IP address). Then they only add to the counter if you are a unique visitor, each day. So if you were to visit a site, but scan through 10 pages, then go somewhere else, then come back hours later, and view 5 more pages, you would still be counted as 1 visitor.Even nastier, you can call in through your ISP, visit, and leave, and disconnect from your ISP. The next guy that calls in to the ISP can get the same IP address (since it may be a shared resource), and get on to the same site, and of course that kind of counter will say, "they've visited before today" and not add to the visitor count.
Conclusions
So you can see that projecting counts (and most counters) are rough approximations. There are many ways they can be done, and many different results depending on the way you count, how you set up the pages, and the profiles and configurations of users, and the way that your users connect to the Internet itself.
The best way of calculating count, is to actually analyze the log-file on the server itself. (This registers each and every transaction and "hit"). And filtering out hits that don't count -- like ignoring all image hits, and only counting unique HTML pages, and so on. It is the best way to calculate all visits (that weren't cached). Using this method on a few different months of traffic (and comparing counter results to log results), I found out that my counter is off by a factor of 3 (actually about 2.68, + I've had the server itself have to be reset from backup and set my count back each time). The end results being that I am getting about 3 times the visitors that I thought I was, and that was being logged. Wow! I've going to figure out a way to correct for this if it kills me.
I've also been able to analyze (at a very high level) where users came from, what browsers they use, and so on. All interesting statistics. For example, I learned that there is some poor sod(s) in Estonia that have hit my site about 3 times a month -- but have yet to get a successful connection (their requests got to my server -- but my responses never got back). It also changes my math and understanding on some things. Like I believed that I would get about 1 email for every thousand visitors -- it looks like that is more like 1 in 3,000. All interesting and nifty stuff, that seems to have little relevance on anything -- but good to know (maybe I need a local mirror for those poor Estonians). Anyway, I was just so happy that 3 times as many people were visiting, as I previously thought were visiting, that I decided to write a long article about counters, just so that I could brag about that little point. I hope you learned some things along the way.
|