![]()
Advocacy
Dojo (HowTo)
Reference
Markets
Museum
News
Other
![]()
Myths
Press![]()
General
Hack
Hardware
Interface
Software![]()
Standards
People
Forensics![]()
Web![]()
CodeNames
Easter Eggs
History
Innovation
Sightings![]()
Opinion![]()
Martial Arts
ITIL
Thought![]()

![]()
![]()
![]()
|
Lately I've been asked, "why do PowerPC's run at slower MHz than Pentiums?" -- or -- "Why doesn't Motorola / IBM just make the PowerPC go faster (run at higher MHz)?" -- after all, the processes used to manufacture PowerPC are often more advanced than Intel's -- so they should run faster, right? Well, processors are very complex beasts, and there are many engineering tradeoffs. One of the most complex tradeoffs for MHz vs Performance has to do with what is called a pipeline.
What is a Pipeline?
Before we go on to discuss how pipelines effect performance, I need to explain what a pipeline is.
It was learned that processors could be sped up if we broke down the instructions on an internal assembly line. Instead of the processor trying to do everything to decode and make an instruction work (all at once) we could do an instruction into stages. Each stage would get part of that instruction done, then it would advance to the next stage -- where the next stage could be done.
Lets break a processors instruction down into 4 parts (stages) in a pipeline (fetch, decode, execute, write):
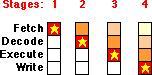
Don't worry about what each stage is trying to do, just try to understand the concepts of the stages.
- In the first stage, the fetch unit does the fetch of
our instruction.
- In the second stage, our instruction advances to the
decode unit and gets "decoded" -- but notice, that the
fetch unit is available -- so we can "fetch" the next
instruction at the same time we are decoding ours. The
processor is doing parts of 2 instructions at once
now.
- In the third stage, our instruction gets "executed".
Also the instruction behind us is getting decoded, and a
new instruction is getting fetched.
- In the final stage, our instruction has done its work, and now any data just needs to be written back (results stored) -- and we are done.
In our example it takes 4 cycles to get our instruction through the processor (this is called the instruction latency or how many cycles it takes to complete our instruction). Notice that there are other instructions stacked in this "pipe" immediately behind us -- so instead of the instruction behind us taking 4 cycles of its own, it only takes one additional cycle to get completed -- and in the pipe right behind that, are two more (partially completed) instructions.
What this "pipeline" (staged computation) does, is allow us to work on many partial instructions at once. Designers are freed from having to wait for one instruction to get all the way through the pipe (processor), before we started working on the next instruction -- just like we don't wait for a car to go all the way through a manufacturing assembly line before we start working on the next one.
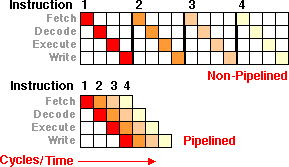
Where non-pipelined it would take 16 cycles worth of time, a pipelined processor will only take about 7 cycles (or about twice as fast) to get the same amount of work (instructions) done. Of course each stage in the assembly line, has a simpler task to do. The latency (time for one instruction to get completed) did not get any better (and often we add stages, so it may actually be worse) -- but the time to get 4 instructions done is much faster (meaning the thru-put got better).
Notice there is some performance tradeoffs going on. Let's assume that without pipelining, we could actually do the instruction in 2 or 3 cycles -- but with pipelining it takes 4 discrete stages (cycles). The time it takes to execute a single instruction gets slower by adding stages in a pipeline -- but the time it takes to complete many instructions gets faster. That balance is important to remember.
How does a Pipeline effect MHz?
What we did was increase the parallelism of the processor (it was working on more things at once), and we increased the thru-put (how fast it could crunch instructions, once the entire pipe was full) -- which are both good things.
The more stages we create for the pipelining, the simpler each stage is, and the easier it is to speed up the clock and make the processors MHz faster.
So deeper pipes are better right? Not always. When we deepen the pipe (and add more stages) we also increased some not so good things as well -- like the latency (how long it takes to get a single instruction through the pipe and completed). In some ways we also have to increase the size and complexity of the processor so that it could handle many stages separately (which increases the size, cost, and power required for that processor). Many are still thinking that the more parallelism and thru-put the better, and once the pipe is filled that processor can keep pushing out instructions (one per clock) -- so deeper is better (if you can afford the space for the pipes). Which is partially true, unless the pipeline stalls or gets bubbles. Read on.
Remember, engineering is about tradeoffs -- and Pipelines cause a few.
Stalls
One of the tradeoffs with making a deep pipelining is what is called a stall. What happens if you have a really deep pipe, and one of the stages is dependent on another instructions data, and that instruction hasn't been completed yet?
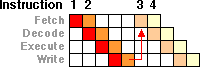
This is what a stall could look like. Instruction 3 can't start until something it needs from Instruction 2 is finished (written). So there is this big fat bubble of nothing going on, while instruction 3 is waiting for Instruction 2 to complete (it is blocking up the queue / pipe). So pipeline stalls are a big deal -- and the more stages you have, the worse they can be. This is only a 4 deep pipe -- imagine a pipe that is say 14 stages deep. For 14 cycles your processor is waiting, and doing nothing! If you are getting a lot of stalls, a 4 stage pipe takes a small hit and goes on, and can be much faster than a 14 stage pipe that is stalling (and taking lots of 14 cycle hits). So there is a real balancing act on thruput vs. latency, and in what it takes to keep pipes filled.
What causes stalls?
Of course dependencies cause pipeline stalls, but there are many things an instruction is dependent on. Lets look at some of the things that can stall a processor and slow work down.
The most common dependency (and what we were talking about so far) was a simple load or store dependency. Loads / Stores are can cause pipeline stalls (as well as the bigger cache stalls). Many instructions are dependent on another instruction or data being loaded or stored before they continue. So the pipe sometimes has to wait for a previous instruction to finish loading, or storing its work, before things can go on. The processor has special logic to race ahead and try to "prefetch" instructions, so that everything we need is preloaded, and when it isn't there we get a stall. While a pipeline stall on a load/store may be a big thing (wasting time for the pipeline to refill), they also have a far bigger danger. If we don't have the data we need in the pipe, then the processor looks in our (L1) cache for it -- if it isn't in our cache, we have a cache stall -- and that can be a bigger hit than a pipe stall.
Cache stalls -- Another type of stall, is called a cache stall. Each instruction has to be loaded, and have all its data loaded. If the data an instruction needs (or the instruction itself) is not loaded, then we have to wait for the "fetch" part of the processor to go and get it. The fetch logic tries to think ahead, and tells the cache what data it is going to need in a few instructions, and get the cache to "prefetch" it -- but sometimes it misses.
If that data (or instruction) we need is in the L1 cache we load the instruction/data from the L1 cache and go on (takes a single cycle). But there are cases where the L1 cache hasn't preloaded what we need -- then we have an (L1) cache stall. Then we have to go to L2 cache (which takes more time). The L2 cache is bigger (but slower) yet it's likely to have what we need -- if it does, we get what we need and go on (which takes a few cycles, say 8 - 14 cycles). But if it isn't in the L2 cache then we have to go to main memory -- this is an L2 cache stall (or a complete cache stall). Since processors are so much faster than main memory, this can take another10 or 20 cycles (or more) -- which is a really big stall. That is like 30+ instructions total that we could have completed all just wasted waiting for memory.
The larger the L1 (and L2) caches, and the smarter their prefetch logic is, the less cache misses (the fewer the stalls, and the less time is wasted). Since memory isn't as fast as processors, just making the processor faster (MHz), may only increase the amount of burnt cycles (time wasted) when you get a cache stalls -- more importantly, the processor may stall more often, since it eats through its caches all the time (which causes stalls) -- in which case you aren't really speeding up the processor, just waiting for memory more often. So designers have to balance MHz and memory performance in order to reduce these cache stalls (misses) with bigger and smarter caches.
So one of the tradeoffs (part of balancing a processor design), is deciding how much logic (space) you are going to spend on different processor parts -- how much area you are going to put towards "pipes" (how deep the pipes are / how many stages) and how much you are going to spend on the size and smarts for your caches (so that they don't stall).
Reordering (out-of-order execution). Remember, that when a pipeline stalls it can't go on -- or can it? Sometimes the instruction order does not matter -- so if one instruction is stalled (say instruction #3 in our example) we can stall instruction 3, but let instruction 4 jump ahead in line and get done first (if it doesn't have any dependencies on instructions 2 or 3). Maybe even 5 can "take cuts in line" as well (as long as it is not dependent on instructions 1, 2, 3, or 4).
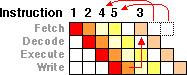
Now reordering is very complex (more complex that I'm explaining), and it can only work in certain cases, but it is one way to reduce the pain of pipe-stalls -- yet it requires logic on the chip. That logic requires more space, and size is also heat and cost (and complexity) -- and the deeper the pipe, the more complex your reordering logic (and reorder buffers) have to get. And you can't use that chip area you are using for reordering for other things, like increasing the cache, which may have increase performance more than just allowing things to "cut" in line. Again, we are back in this tricky area of balancing the tradeoffs, with power, size, cost, and design complexity -- and the deeper your pipe, the more reordering logic you need (size and complexity) to balance out the pipe-stalls.
Another thing that cause pipeline stalls are Branches (conditionals). All the time (say one out of 4 - 20 instructions) computers are deciding "should I do this" (and jump to this location) or "should I do that instead" (and not jump, or jump somewhere else). The trouble is that the prefetch logic (for the cache and pipeline) has a tough time deciding which way it should go before hand -- after all, it doesn't know what the instruction is before it has looked at it (and run it). If it fails to predict correctly, then it hasn't preloaded the pipe with the right instructions, so the processor throws those bad pipe data/instructions out, and has to start loading at the correct location (big pipe stall and cache stall). Designers put "branch prediction" logic in to reduce these branch misses (stalls), and they can be pretty good at guessing which way the the branch will go (most of the time). But that logic takes space -- which is the same as size, cost and heat. The deeper the pipes are, the far bigger the hit (in time) on a branch prediction failure -- so the deeper the pipe, the more area and design time you need to spend on branch prediction logic to avoid those bad stalls (on a shallower pipe, this stall isn't much of a hit, so you don't have to worry as much).
There is another trick that designers try to use to save time and pain of pipe stalls (which increase the chances for big cache stalls). Since there is a bigger penalty on deep pipes, you have to add even more logic, to see if you can only "partially stall" the pipe. You use shortcuts to reduce the hit on pipeline stalls.
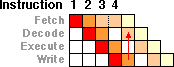
So for our example, we can fetch instruction 3 ahead of time (even if it dependent on results from 2), we just can't decode it until we get the information from instruction 2. But when instruction 2 is complete, it can shortcut and tell the decode unit directly where the needed results of instruction 2 are, and instruction 3 can go on (instead of waiting for the fetch unit to figure it out). We reduced the stall penalty by trying to get as much done as we could -- and might shave some cycles from a stall. Now on a 4 stage pipe, this is not much savings (one cycle), but on a deep pipe, you really need to make sure that stalls only stall for a small part of the pipe, so that everything is ready to continue when the dependency is done. This can reduce a 14 cycle stall, down to 8 cycles, or maybe even 4 cycles -- at least some of the time. Again, the deeper the pipe, the more you want to add partial stall logic, and the more complex that logic and the whole pipe architecture gets -- and of course the more size that logic takes, which means more heat, costs and complexity, and less area for doing other things that could increase performance.
Conclusion
|
Hopefully, you can see that there are a lot of things that go into pipelining a processor. Deepening the pipe usually means that you can speed up the clock rate -- but it also means that you get less done on each clock (each stage is simpler). Processor designers are fighting a balancing game of getting more done on each clock, or just increasing clock rate (and increasing the pipe depth) to get the same (or more) work done (because they had more clocks/cycles). Remember, that deepening the pipe also has many other ramifications - like more logic required for the pipe itself, and since the penalties for stalls are bigger (and staging more complex), and you spend even more logic handling things like instruction reordering, branch prediction, partial stalls, and other things, all to make your stall penalty less.
Hopefully this helps you understand how more MHz does not mean faster performance -- it is just one way of increasing performance. There are some extreme cases like IBM's Power3 (PowerPC 630) which at 200 MHz is faster than an UltraSparc2 at 400 MHz, and faster still than a Pentium II Xeon at 450 MHz.
So once again, some poor guy asks me a simple question, "Why aren't PowerPC's running at the same MHz as Pentiums, and why are they still faster if their clock rate is slower?" -- and I have to go into a terribly detailed explanation. However, if you suffered through the explanation, then you now know a heck of a lot about processor designs, and can amaze and dazzle your friends, and be the geek at every party (debating with others about pipeline depth vs. architectural simplicity and cache size). Have fun with it and see how many parties you can get thrown out of for obnoxiously technical behavior.
|