![]()
Advocacy
Dojo (HowTo)
Reference
Markets
Museum
News
Other
![]()
Myths
Press![]()
General
Hack
Hardware
Interface
Software![]()
Standards
People
Forensics![]()
Web![]()
CodeNames
Easter Eggs
History
Innovation
Sightings![]()
Opinion![]()
Martial Arts
ITIL
Thought![]()

![]()
![]()
![]()
|
Motorola just announced AltiVec extensions for the PowerPC family. The extensions are somewhat comparable to the MMX extensions in the Pentium family. But, while MMX injects "fun" into your computer, AltiVec focuses on performance.
Nearly a year ago I explained what MMX is, and what it can and can not do in the MMX vs. VMX article. I also speculated on VMX (the code-name for AltiVec). It is probably still a relevant read for understanding MMX and AltiVec.
SIMD (how it works)
Normally a single instruction works on a single chunk of data (we could call this SISD, but we won't). However, unless your data is the exact same size as your computer, lots of the potential processing power is wasted. Modern computers are 32 or even 64 bits wide, but lots of data may be 8 bits wide. Imagine you want to work on a byte of data (being used for a character, or for a pixel, or for a color component of a pixel), and you have a 32 bit computer. To do so, you must process (run instructions) just to get to data you want to work with (since it is a sub-component of the 32 bit word), and then you can only work with 8 bits at a time. Basically, you end up turning your 32 bit computer into an 8 bit computer. If that doesn't sound efficient, it is because it isn't.
Unused Space Used Data <----- ALL 32 BITS (what the CPU works with) ------>
SIMD is a way to work with all the data at once (in parallel), which can make your computer far faster. Instead of breaking down a 32 bit (or larger) chunks of data, into their 8 bit components, and then working on them, "one at a time". We can treat all the 8 bit components as items (vectors) in an array, and work on them all at once.
|
|
|
|
|
|
|
|||
Let me explain more by example:
Image Filter
Let do something we might do in programming -- a simple image filter (like in Photoshop, or scans). Imagine we want to diminish the "red" in a picture (or in this example, just on a single pink pixel). I have to do the following:
- Load each pixel (dot). A pixel is made of 3 component colors (red, green and blue -- each of which is an 8 bit value).
- Mask out all information that is not the red component.
- Align the value to work with it (the computer often requires right alignment before doing math).
- Lighten the red (lessen the saturation by subtraction, division or shifting).
- Align the value back to where it was.
- Mask the red out of the original pixel
- Add the new red to the old pixel (to make the new pixel)
- Store that pixel (dot) back in the image (which is now a little less red, or more purple than pink).
What SIMD does, is allow me to do math on each pixel in parallel. So it would do the following:
Load a bunch of pixels at once
- Load a mask
- Do all the divisions on all those non masked pixels at once
- Store all the pixels back at once
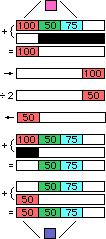
So in a single instruction, the processor worked on multiple pieces of data (SIMD). The wider (larger) the data that SIMD can work on, the faster it is. In AltiVec's case it is 128 bits at a time, so it could do up to 6 red components at the same time. Instead of behaving as a single 8 Bit processor, SIMD let our processor behave like 16 different 8 bit processors (that just happened to be doing the same thing to different data) -- but only 6 of those processors were being used for our instruction. (In some cases, all 16 will be used). Not only does SIMD allow us to do more at once, but it is more efficient by how it works as well (it is doing special vector math operations, and designed to do more the type of things we need, for some tasks) -- so it takes fewer steps to complete (only 4 instructions instead of 8).
Remember, that we have to repeat our loop for each pixel in an image. On a 640x480 image (an image the size of a 13" monitor), that has to be done 307,200 times. Good thing computers are fast. So to compare SIMD to Non-SIMD on a 640 x 480 image:
- Without SIMD (the regular way) requires 307,200 pixels to be processed, times 8 instructions for each pixel, for a total of 2,457,600 instructions.
- SIMD requires 307,200 pixels to be processed, but it works with 5.3 pixels at a time, and only requires 4 instructions for each pixel, for a total of 230,400 instructions having to be done. Or SIMD is about 11 times faster. WOW!
That is assuming that we are using millions of colors mode. If we use thousands of colors mode (16 bits for color instead of 24 bits) there can be a bigger difference. The normal way (sans-SIMD) would see no additional performance gains. SIMD would see about 50% performance gains, and could now be up to 16 times faster (total). And this is only one example, it can make a difference elsewhere as well.
Another example is reordering bytes. This can take up to 5 or 6 instructions to reorder each byte in an array or string (in programming there are many reasons to do this). To do that on 16 bytes could take 80 - 96 instructions (total). There is a single instruction (called "permute") to do all 16 bytes at once using AltiVec -- thwack, up to 96 times faster, and this (reordering) is a pretty common operation. But speed improvements of this magnitude are rare.
The point is that AltiVec works in parallel, and makes the computer much faster for certain things. The amount of parallelism is determined by the size of the data. If you are working with 64 bit data, you can work with two at a time. You can work with 4 x 32 bit data "registers", or 8 x 16 bit registers, or even 16 x 8 bit (1 byte) registers. There is even a special mode for dealing with 1/5/5/5 for 16 bit color (thousands); which is really 3 x 5 bit component colors and 1 bit at the beginning -- AltiVec can work with 4 or 8 of these groups at one time.
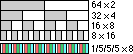
So AltiVec is like having up to 16 (8 bit) processors (computers) inside, all working at once. Or it can work as one 128 bit processor, or just about anything in between. FAST and powerful, and very neat -- for some things. But remember, just because it is dramatically faster for some things, does not mean that SIMD can improve everything. In many cases there are setup costs, or some design penalties that can make it not quite as much faster as it seems. Also you have to remember that even if a programmer has to do this 10 times in each program, there may be tens of thousands of other things that program has to do. So the performance increase is dramatic -- but rare. Yet, if you are doing a lot of one of those things that SIMD can speed up, the performance increase is awesome (1).
(1) In the real world, SIMD can make certain things fly, like image processing, 3D, drawing, doing video, sound, speech recognition, networking, or doing NSP/DSP (Signal Processing) type functions. It can improve just plain moving memory (used a lot in computers), or table lookups a little (also used a lot). But SIMD doesn't effect other performance as much. Overall, it will probably only double the zippiness of the computer -- but do so by making some things 4, 10 times faster, and hardly effecting most things at all.
Comparison
By now, you may be thinking, wow, MMX and AltiVec are cool -- and they are. But AltiVec is far cooler. Remember, the PowerPC is a RISC computer and has room to do things right. The Pentium is still an older CISC, and is lugging around 30 year old baggage, which gives it less room, and makes things more "crammed" -- so they can't implement things as well. Look at the following:
AltiVec MMX Size:
128 Bits at a time 64 Bits at a time Instructions:
162 New Instructions 57 New Instructions Registers:
32 New Registers 8 Registers (replace FP) Unit:
Independent tied to Floating Point unit
Remember, "Wider is Better", or more is better (in this case). AltiVec is twice as large -- or up to twice as fast (effective). Then if that isn't enough, many of the "neat" performance increases, require special instructions (for doing exactly what you are trying to do). AltiVec has nearly 3 times as many different instructions. But it isn't just quantity of instructions that matters, it is quality as well. AltiVec has classes of function like table-lookups, and 32 bit floating point, that MMX can't do -- and these can be VERY useful. Also more registers matters, since you don't have to "unload" (forget) one thing, in order to work on another. AltiVec has 4 times as many registers. Then comes the biggest difference -- AltiVec is a dedicated processing unit.
Each processing unit can work independent of the others. So while one PU can be doing one thing, another can be doing something else -- this translates to more parallelism (but by separate units). So Motorola designed AltiVec to be a separate unit. But Intel tied MMX to the FPU (Floating Point Unit). So on Pentiums you can do floating point math -or- you can switch over to MMX -- but you can't do both. The switch requires a "mode change" that can cost hundreds of cycles, both going into and coming out of "MMX" mode. Since some computing algorithms require "mixing" of modes, it makes it very tricky to write good MMX code, and often requires more inefficiency (since you have to do one pass on the data in MMX mode, and another in FP mode). AltiVec can vectorize the floating point stuff too - so you might way that it "doubles" the benefit. With AltiVec you can to start work on some data in the FPU (Floating Point Unit), then load that data into the AltiVec side (Vector Unit) without any big mode switch. This saves hundreds of cycles, and allows programmers to do more with the Vector Unit; since they can go back and forth and mix and match.
Intel has realized, and in fact known about this flaw all along (mode switch penalties). They are talking about fixing it in the next generation, or so, of their processors; and coming out with "MMX-2". This is typical of them, design it poorly, try to fix it later, and force users (and programmers) to suffer. So MMX-2 may do what Intel promised for MMX -- but I'm not holding my breath. Programs will have to have 2 different versions of "MMX" routines, one for "MMX-1", and another for "MMX-2". Or programmers will give up and support neither -- especially since the other clone-chip makers, may or may not support MMX the same, or at all.
Remember, that some math filters require "mixing" of floating point, or transitions to and from floating point. 32 bit floating point math isn't even done on MMX, but AltiVec can do four of these instructions at a time -- and this is the exact kind of math that is cool for some filters, 3D transforms and things that you want to use SIMD for.
Support
The biggest problem with MMX or AltiVec is getting programmers to use them. MMX required hand-tuned assembly language to use (see "pain in the ass"). As such it was only used by a few (very few), for a dedicated few applications -- like Intel hand tuned some Photoshop Filters for Adobe, so the Pentiums wouldn't get "as" stomped in comparisons. Pentiums were 2 or 4 times slower than PowerPC's. But since MMX doesn't support floating-point with MMX, Intel could only speed up a few limited filters (in limited size), and the PPC was still fast(er) enough that it can hold its own. So now Pentiums with MMX are nearly as fast as PPC's (or even a smidgen faster) in some certain cases, but still slower over all.
While MMX can only work on filters with certain "sizes" -- like a 2 pixel Gaussian Blur, and so on, these "sizes" can be twice as large (or larger) for AltiVec. So AltiVec can accelerate a 4 pixel Gaussian Blur as well, and be beneficial on larger size (while it might not make a difference with MMX). Also AltiVec's mix and match with floating point means that it better still, and can be used more implementations.
Programmers can write for AltiVec using C (instead of assembly required for MMX). Meaning it is far more likely that people will actually use AltiVec. Plus the PowerPC compilers can already do special instruction scheduling (optimizations) to make the code faster -- MMX requires hand tuning.
Then there is the OS itself. Microsoft has done little (nothing?) to support MMX. Mainly because the quality of the MMX instructions aren't that beneficial. There is also the value of the "return on investment". With MMX you may get a two or three fold increase on certain routines -- but overall, that may only be a 10% performance increase, and may not worth all the effort (especially if you have to program in assembly). But AltiVec is more likely to give you 20-50% performance overall, and it is usable in more cases, and it is easier to program. (Since you program in C, using AltiVec may be just a push-button recompile). So AltiVec requires far less investment, with far greater returns -- so I expect to see it used more in the OS itself (as well as Apps).
Apple (MacOS) also has an architecture that is a tad more modular, like QuickDraw, QuickTime, QuickDraw 3D, Open Transport and so on. Apple could recompile or optimize for those components, and all apps that use them (which is most) would feel the benefits of AltiVec. Apple is also far more likely to actually use technology in a timely manner (right now Apple's even supports MMX for QuickTime on the PC. Ironic that Apple supports the Pentiums better than Microsoft). So it is likely that parts of the OS will use AltiVec, as well as the apps that need the performance the most.
Conclusion
So the points are:
- SIMD implementations can make a huge performance difference for certain things.
- AltiVec is a far better SIMD design and implementation than MMX.
- Quality of design (and implementation) will contribute to the support each implementation gets, and support creates more support (acceptance builds momentum).
- MMX still hasn't achieved a critical mass, other than a few Applications, and the implementation is lackluster enough that it barely surpasses a stock PowerPC.
- MMX is going to have the added complexity of multiple implementations, both for MMX-1, and MMX-2, as well as whatever various chip cloners use, meaning it is more work to support.
- AltiVec is a high quality Vector Math and SIMD implementation that is easier to use, and takes the PowerPC to the next level -- so it is likely that by the time the processors are available there will be some support.
I suspect that in a year or so, AltiVec is going to creep into many parts of the MacOS and various application to increase performance -- above and beyond the other performance increases we are going to see because PowerPC's are going to be using Copper Process and possibly going as fast as 600 MHz.
The fact that RISC requires fewer gates (area) to achieve the same performance levels as CISC (Pentiums), should guarantee that they will always have the space to take computing to the "next level" and create a superior implementation of technology -- as AltiVec seems to show. Sometimes it is not about who does it first (though others did it far before Intel did), it is about who does it best!
Other Articles
- Motorola AltiVec Home Page - technical and marketing information
- MacCentral - technical summary
- News.com - preview of the announcement.
- http://www.sci.fi/~saffron/transamour/altivec.htm - excellent article
|