![]()
Advocacy
Dojo (HowTo)
Reference
Markets
Museum
News
Other
![]()
Myths
Press![]()
General
Hack
Hardware
Interface
Software![]()
Standards
People
Forensics![]()
Web![]()
CodeNames
Easter Eggs
History
Innovation
Sightings![]()
Opinion![]()
Martial Arts
ITIL
Thought![]()

![]()
![]()
![]()
|
If you haven't read it yet, you should probably read Takin' the Bus article first.
This article is going to explain relative sizes of information that can be passed inside of a computer (usually on a Bus). Some call this plumbing because it is easy to think of busses (the things that carry data around in a computer) as pipes, and to think of the data as water flowing through those pipes. Understanding this will really help you get an idea of how information flows inside a computer, and what is "fast" and what is not as fast.
Just because a pipe has a POTENTIAL size, does not mean that the potential will always be used. In other words, a pipe has a diameter, but that whole pipe my not be kept filled with water (data) ALL the time. If the pipe is fully filled, and is passing all the data it can at a given time, then we call that "saturated" (you can't put more data through faster than that rate). Not only that, but the water may be pooling at the sending end, waiting for it's chance to be sent. When that reservoir (also called a cache, buffer or queue) gets filled, then the entire system may have to wait for the bus to clear (like a traffic jam on the freeway). We call this being "bound" (tied up), as in I/O bound, processor bound, memory bound or so on. This narrow point in the pipe has become a "bottleneck" (or choke point) and everyone has to just wait around for it to clear up again. We don't like this wait -- whether it is for our sinks, for our cars, or for parts of our computer. In that one paragraph you learned all the technobabble that this article will use, and what it all means.
I was going to draw a computer system internals
(architecturally) and explain the I/O sizes and paths to a
relative scale (the size of one data "pipe" relative to the
speed of all others). So I took a single pixel line
"![]() ,"
and figured if that was the amount of data that a modern
modem could handle (56 Kb), then how big would the main
processor bus be (to scale)? My answer -- 87 feet across.
Since I didn't want people to have to scroll that much, I
figured to hell with scale. But I'll still try to give
people some ideas of scale on a part by part basis. Also
because of the dramatic differences in speed, I broke the
article into internal pipes, and external ones (I/O). This
one is about internal.
,"
and figured if that was the amount of data that a modern
modem could handle (56 Kb), then how big would the main
processor bus be (to scale)? My answer -- 87 feet across.
Since I didn't want people to have to scroll that much, I
figured to hell with scale. But I'll still try to give
people some ideas of scale on a part by part basis. Also
because of the dramatic differences in speed, I broke the
article into internal pipes, and external ones (I/O). This
one is about internal.
NOTE: Width of the arrows I am using are only showing the relative amounts of data that can be sent in a given time. They are not meant to show whether that data is being sent in serial (1 bit at a time) or parallel (many bits at once). It is only reflective of the total data rate.
Fast Pipes (main busses)
CPU's (Processors) are very fast. If we were to take a 266 MHz processor, and talk to different components, it might look as follows.
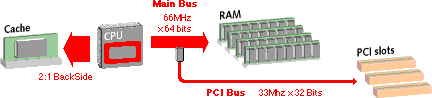
Notice that the arrow to the L2 Cache is very wide (and short). That is because the L2 cache is very fast. It is very short because the closer something is, the faster it is to talk to (1). This L2 cache can output at 133 MHz x 64 bits (or 1 Gigabyte/Second), if it is a 2:1 backside cache. A 1:1 cache, or the CPU's internal cache (L1) is twice as fast (2 GB/sec). (If you notice the red circle around a part of the CPU chip, that is meant to represent the L1 cache or internal cache, and the CPU's internal bus, which runs the full speed of the CPU).
(1) Imagine trying to shout to someone that is ten miles away (with a really good megaphone). You would have to wait until the sound got to them, they registered it, and yelled back, and until you processed their reply (figured out what they were saying) and so on. Not only that, they tend to speak slower, just to make sure that YOOOUU WIIILLLL UNNNDEERRRSSSTTTAAAANNNDD TTHHEEMMM. It would certainly be slower than talking to someone right next to you. Computers behave the same way. But computers are so fast that the difference between 2 inches and 6 inches is a noticeable delay, and they are talking closer to the speed of light. These speed lags are not only because of the speed the information travels, but also because the further the distance they are going to travel, the more they have to shout (use higher voltages, charge things to drive that distance, wait for responses, and so on), and that slows things down (just like you had to slow down to take deeper breaths and make sure the other guy would understand you). So speed and distance are intertwined in computers, and in the rest of the universe.
If you notice, the speed across the main bus is not quite as fast (the pipe is not as wide) as the backside cache BUS. So the Main Bus is only about half as fast as the backside cache bus, or in other words, the Main Bus can transfer about 500 MB (Megabytes/second). This means that main bus is likely to slow down the processor a lot (compared to the processors internal bus, or its backside cache bus) -- and it does. But it only slows it down when the CPU has to go out to that bus (which is not that often). In computers, you may have to do ten things (instructions) to each piece of data before you store it or move it. This means that most of the time a processor is working with what it has looked at before (recently). So this minimizes the traffic on the main bus, if you have a cache.
Remember, Computers are fast. They are fast on scales that people aren't used to thinking about. If a processor (computer), is ONLY going out to access memory 1 out of every 100 instructions, a 266 MHz computer might be hitting the main bus 10 million times each second. (For those confused by my math, remember that some computers are doing more than instruction at a time).
To make memory performance issues worse, the RAM (memory) can not even keep up with the main bus (by about half). So while the pipe (main bus) is as large as represented (it has this much potential), the reality is that the memory can not saturate this bus. Or, in less techie words, the RAM can't keep the pipe filled (fully utilize the BUS), even in a perfect world.
What need are faster types of RAM -- but by the time we get those (for our next system), the main BUS will be wider and faster too. So RAM is just not keeping up with bus speeds -- which means that RAM is a bottleneck (a slow point).We hide the RAM bottleneck with the faster and larger caches (L1 and L2). These pools of often accessed memory, is very fast, so that we don't need to access slower RAM as often (and we use the main BUS less as well). This hides the symptom of slow RAM.
Now before you get too smart, and wonder why we need such a fast main bus, if we aren't able to use it (saturate it), the answer is that we can use that BUS for other things besides RAM. A RAM bank can't saturate the pipe by itself, but two RAM banks can take turns trying to fill the pipe (main bus). That would make the memory almost twice as fast, and it come much closer to saturating the BUS (we call this technique memory interleaving). There are also certain types of RAM (Static RAM) that are fast enough, but they are also too expensive to use for much other than cache (on home computers). Also remember that the main bus doesn't talk only to RAM, there are other chips out there that can talk to the CPU faster than RAM can. In some systems we can put two (or more) processors, and they can talk to different things (alternately) and keep the bus more filled. So the BUS speed is important, but not quite as important as some people seem to think. It is always a balancing act between keeping the pipe big enough to move around what we need, but not so big that it is just sitting around being unused.
Now notice that the PCI BUS is about 1/4th the size of the main bus. It can transfer data at a theoretical maximum of 132 MB/s (Megabytes per second). But there is more than just theoretical speeds in this shared BUS. By the time a card gets control of the bus, and gets its turn to talk and leaves time for the others and so on, I think the real world performance is about half the theoretical number.
Devices on a bus, are often like a conversation in a small group -- one should wait for the others to finish before they start talking, and there are supposed to be occasional pauses to see if anyone else has something to add. Or there is sometimes one person controls a conversation or debate. That person says who's turn it is to talk next, and when their time is up, and is often called the "arbitrator". The last techie terms of the day are "Bus arbitration", which has to do with controlling who's turn it is to talk on a shared bus -- or Bus Collision, which is what happens when two people (devices) try to talk at the same time (hopefully, they both just stop and try again later).
Things are always getting faster, but they seem to get faster in balance with each other. In another year or so, they are talking about doubling both the speed and the width of the PCI Bus (66 MHz x 64 bit). Either one alone will double the performance of this pipe, and together, they will quadruple it to 528 Megabytes/Second. Of course, our main bus will increase around that time as well (to 83 or 100 MHz), and do to some complex things, the main bus has an easier time with arbitration (and has less overhead). So main bus (memory bus), is likely to stay ahead of I/O Bus (PCI Bus) for quite some time.
Because the PCI Bus is so slow (relative to main Bus), we sometimes go around it. We put an expansion card directly on the main bus (with very few "tweaks"). This is called a DirectBus (or Apple called it a PDS, Processor-Direct-Slot), or Intel calls it AGP (Advances Graphics Port). But they are all basically the same thing, hanging a special type of card, directly off the faster main bus, and going around PCI. Since the only thing that really needs this is replacement processors, specialty processors, or some graphics cards, that seems to be all these are ever used for.
So already you've seen how while a processor bus can talk at speed up to 2 GB/s (2 billion characters a second), by the time you get down to a bus that talks to the I/O cards, the speed is probably only 64 MB/s (64 million characters a second) -- or 32 times slower. But keep some perspective, that is the equivalent of 32,000 pages of text being moved around every second, or it could process somewhere between 2 to 20 TV channels worth of information simultaneously.
Conclusion
So this article explains some performance differences among the internal pipes and understand some of the basics. But there is a lot more to cover.
Read the External Pipes: I/O and throughput for more. When it is finished.
For now, I hope you get some of the basics of the internal "data pipes" inside a computer.
|